¶ How to Update your VergeIO Environment
WARNING: DO NOT SKIP MAJOR VERSIONS. For example, if you are on version 4.8, please update to version 4.9 before updating to 4.10. Skipping versions could cause major database and configuration issues.
The VergeIO platform supports 'zero downtime' updating. This means that during a routine update process, guest workloads (VMs and tenant environments) can be left on and running as normal.
Information on updating the Verge.io software to the latest version can be found in the inline help within the category titled Updates, under the section titled Running Updates. This section walks through the entire update process. Additionally, information about each setting found under Update Server Settings can be found within the category titled Updates, under the section titled Update Settings.
The time frame an update can take to complete varies between every environment. Some of the important factors to consider are:
- How many nodes are in the system
- How much storage is being consumed on the vSAN
- The data change rate being generated by workloads during the update
- The performance of the hardware (processor speed, disk type, network speed)
During the update process, you may see tiers and drives alternate from an 'Online' status to a 'Verifying' or 'Repairing' status. This is normal behavior and is the result of the system verifying data integrity throughout the update process.
Before performing an update, please verify that you are not using more memory than other node(s) can take over running. For example, in a two node configuration, total system memory should be under 50% utilization as the other node will have to run 100% of the workloads.
Please ensure that no nodes are currently in Maintenance mode before continuing.
- Log in to the VergeIO UI.
- Navigate to System > Updates and then select “Check for Updates” in the left menu.
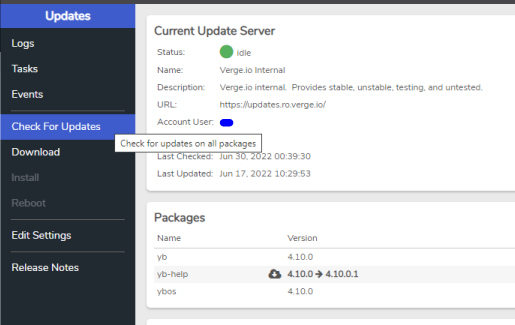
- A pop-up will confirm Yes or No, select Yes.
While the update check runs a banner may appear stating “A new minor version is available on a different branch". This is dependent on the version & release. If the banner does not appear it is safe to move on to the next step.
To change to this new branch, select "Change Branch" in the left menu.
A pop-up will confirm Yes or No, select Yes.

- The packages that are to be downloaded will now be highlighted.
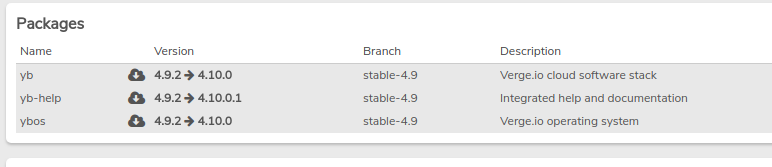
- Select "Download" in the left menu.
- A pop-up will confirm Yes or No, select Yes.
- When the download initiates you will see the download process running on the dashboard in the “Current Update Server” tile.
- Once the download completes, the “Install” action will become available in the left menu indicating that the updates are ready to be saved to the system.
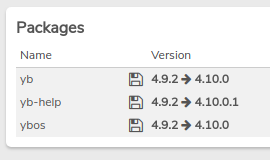
- Select Install in the left menu when you are ready to do the upgrade.
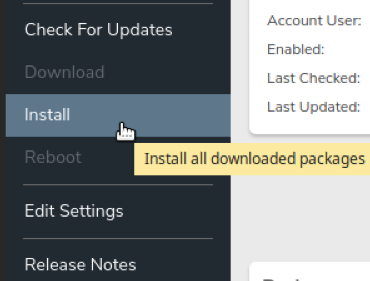
- A pop-up will confirm Yes or No, select Yes.
- A brief install of the new package(s) and then a request to reboot the system will occur.
- Select Reboot in the left menu to initiate a rolling reboot. This will install the new software updates across all nodes in the system.
- A pop-up will confirm Yes or No, select Yes.
Note: The update will start with node1, putting it into maintenance mode. This will migrate any workloads to the next available node. During a minor version change, i.e. 4.9 --> 4.10, you may lose access to your UI briefly while the UI network fails back to node1 from Node2. This is a normal process due to a database upgrade and shouldn't take longer than a minute or two. During this time workloads should not experience any network issues. Once the update is complete on Node1, it will move to the next node (Node2) which will not affect the UI.
¶ Troubleshooting Steps
¶ Workloads are failing to migrate
This will be accompanied by an error stating "Not enough resources to start machine "X"". This is typically due to a constraint on RAM resources in the specific cluster the workload is assigned to. To address the issue, other workloads in the same cluster may need to be migrated or "juggled" to make enough available space to give the migrating workload enough RAM to start on a single node. Other possible causes for failed migrations can be found here.
¶ The vSAN is taking a long time to verify
The verify and repair processes time to completion depends on factors such as core network speed, drive speed, and the amount of data consumed. Any nodes that contain spinning disk will inherently take some time to complete their processes. NVMe and SSD nodes take exponentially less time to complete vs HDD nodes. On any system greater than version 4.9.0 you can navigate to the tiers dashboard and confirm its "Full Walk Progress". This indicates how far along the verification process is.
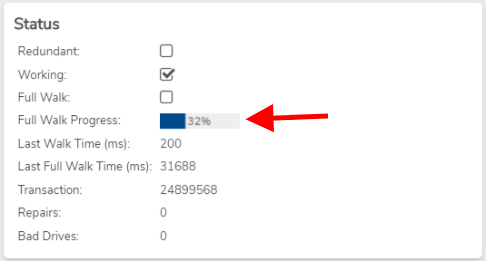
This process must complete before any other nodes are rebooted or a double failure will occur causing workloads to crash.
¶ Unable to Connect to Update Server
- Confirm that the system has a working DNS server on its external (UI) network
- Navigate to the external network dashboard
- Select Diagnostics in the left menu
- Query = DNS Lookup
- Select Send
- If DNS is properly configured the response will come back with an IP address for Verge.io.
- If a reponse of "No Response" is returned check DNS settings in the external (UI) network and attempt a DNS query again.
- Update Server credentials may have expired. These are tied to the systems license and must be obtained from your VergeIO sales representative.
Need more Help? Email [email protected] or call us at (855) 855-8300